I’ll get to the name at the end. In January I took the plunge and procured myself a dedicated track car for my HPDE hobby: a 2006 Mazda MX-5 Miata in Winning Blue.

I’ll get to the name at the end. In January I took the plunge and procured myself a dedicated track car for my HPDE hobby: a 2006 Mazda MX-5 Miata in Winning Blue.
![synology_610x425[1]](http://www.elaske.com/wp-content/uploads/2013/11/synology_610x4251.png) In order to start working on my Synology JIRA package, I needed some way to test without having to sacrifice the stability of my own DiskStation. In order to do this, I decided to use VMware Fusion. This is a guide showing one way to do so:
In order to start working on my Synology JIRA package, I needed some way to test without having to sacrifice the stability of my own DiskStation. In order to do this, I decided to use VMware Fusion. This is a guide showing one way to do so:
An older guide that uses VirtualBox can be found here: http://www.robvanhamersveld.nl/2013/01/21/install-and-test-synology-dsm-in-a-virtual-machine/.
Read More
 Many of the CAD tools that I need to work with on a daily basis are Windows-only tools. I have slowly attempted to minimize the number of those tools that I require and slowly ease into Linux. At this point, the only real tool that I continue to use that is solely for Windows is Altium Designer.
Many of the CAD tools that I need to work with on a daily basis are Windows-only tools. I have slowly attempted to minimize the number of those tools that I require and slowly ease into Linux. At this point, the only real tool that I continue to use that is solely for Windows is Altium Designer.
In part of my move to Linux, I decided to convert my Windows partition to a VHD file to use in a virtual machine in the future. Of course right after I did that, I found I needed to access it without the virtual machine. After piecing a few things together, I was able to mount and access the VHD file successfully.
Up until now, we’ve been starting JIRA by executing [shell]start-jira.sh[/shell] from the command line. Of course, since we’re logged into an SSH session to get this command line interface, if we were to disconnect, the processes we start will all get killed. Having to keep an SSH session open to use JIRA is not exactly the way we want to have it set up. So, what do we need? A startup script linked into Synology’s boot! Read More
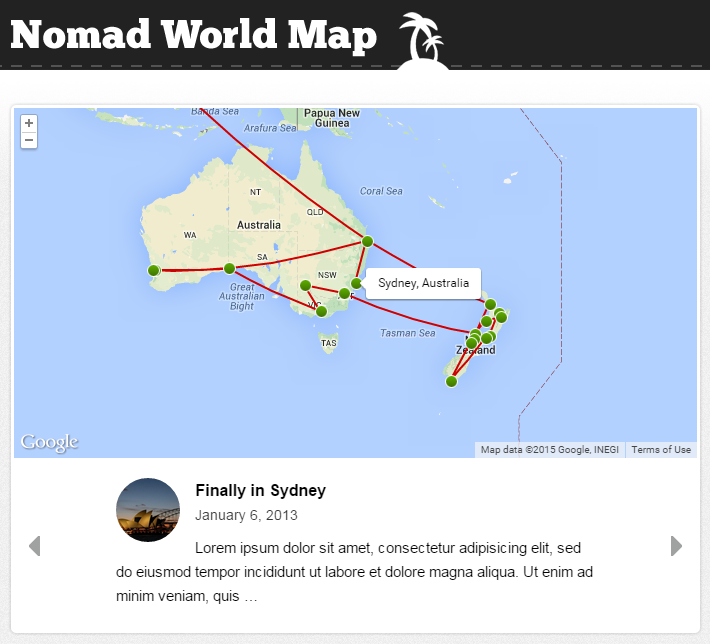 When setting up this site, I knew I’d want to talk about where I’d been. I had done so before previously by putting together a Google Map that had all of my travel destinations for the trip. This got cumbersome and was relatively featureless. I went searching at first for just a way to embed this kind of information into a post or a page and stumbled upon Nomad World Map.
When setting up this site, I knew I’d want to talk about where I’d been. I had done so before previously by putting together a Google Map that had all of my travel destinations for the trip. This got cumbersome and was relatively featureless. I went searching at first for just a way to embed this kind of information into a post or a page and stumbled upon Nomad World Map.
Rather than just allowing embedding of the Google Maps I had created into the post, I was able to create trips within the plugin. I could embed these trips into a post and it would link up with my blog posts about each of the places I had visited! This is a perfect addition to a site with any type of travel blogging. You’ll even notice the ability to embed your current position into your site as a widget!
There was one problem setting up this plugin, though. It’s incompatible with another plugin I had: Page Builder. For some reason the way Page Builder renders the pages is as a widget. This means that the nice full plugin rendering is no-longer available.
The plugin doesn’t seem to be actively supported any longer as a little bit of research into the plugin has shown. However, the author has it posted on GitHub: https://github.com/Tijmen/Nomad-World-Map.

A friend of mine asked me recently: But… why post things to the internet? I originally answered this question with a simple “because I want to document my experience.” That doesn’t really answer the core question. Not why I want to post things, but why to the internet? So, how does one answer that? I think that’s an important thing to define and it kind of sets the tone.
I think the answer lies in how I look at the internet: It’s a collection of knowledge and experiences of vast amounts of people. Google has been the gateway to this database of human knowledge and it’s allowed me to be able to find the answers I need; or, at the very least, the key points I needed in order to find the answer.
At work, I really put emphasis on documentation as much as I can. As I figure things out and implement things, I want to document my design decisions and how I solved certain problems. This allows myself and others to easily solve the same problem if it’s encountered again, or quickly overcome a similar problem.
So, my original answer to that question is still the core of my answer: As I work on projects and figure out solutions, I want to document them. This is partially going to be my own personal story-like Wikipedia. There’s so many times I’ve used other people’s blogs and such to solve a problem, I hope that I can be that person for at least one other person. The only way to really do that is to make sure these aren’t just posted to my own local server’s wiki, but on something that’s available to the world.
Now, then why would I care to do this for my travels? It seems silly because sometimes travel experiences are personal and not exactly universally applicable like factual knowledge. However, I believe that the same thought applies as to other documentation. If someone stumbles upon this in Google and figures out they want to go someplace because they didn’t know about it, or not waste their time in some place I did, then I’ve helped them in some way.
Helping someone out with the knowledge I have is what I hope to do with this site – making some sort of difference in their lives. Maybe it’s not as “grand” as people think when they hear “make a difference,” but I feel that it’s valuable nonetheless.
The TSP decided to change the way that they make the data available randomly since I originally made the script. The old version of the page looked like this:
![Share-Price-History-Data[1]](http://www.elaske.com/wp-content/uploads/2015/02/Share-Price-History-Data1.png)
It only allowed you to access 30 days at a time, and required more of a human-touch to gather all of the data. In order to navigate this, I had to request the data (and resulting page) 30 prices at a time. To load the whole database, this took a considerable amount of time. Read More
Most of my portfolio is in mutual funds rather than individual stocks. This allows me to diversify a bit more easily without the added cost of trading. Also, it doesn’t open yourself up to as much volatility as ETFs can experience, since they’re subject to the whims of market emotions just the same as individual stocks.
Mutual funds have one very big problem, though: you do not know the share price at which you’re going to be buying and selling them like stocks. With stocks, you list a price you want to buy / sell at and your broker makes sure you pay / get paid exactly that (after taking a commission, of course). You have to buy into mutual funds (slightly different than purchasing a share of stock), and have to initiate it during trading hours, usually. Mutual funds have their prices set (actually called a NAV), some time after the close of the market, however – usually around when people leave for the day.
Setting aside the reasons why this is the case (which I understand and am not arguing with at all), this makes buying into and cashing out of mutual funds relatively risky. One nice thing about mutual funds is that they publish their holdings (at least to some people looking to sell that data). The top 10 are freely available at places like Google and Yahoo!; however, Morningstar displays to users up to 25 (they try to charge for the top 100). You can start to predict what the prices of the mutual funds are going to do based on the holdings did that day. If all of the holdings went up 1%, the NAV of the mutual fund will tend to go up 1%. This correlation is less descriptive of funds which you know less of the total composition (say they had 300 positions total), have a higher turnover rate (buying and selling of their positions a lot), or are leveraged (borrowing in order to buy in extra).
So, I decided to make another script to help me with the intra-day decisions about whether or not to buy or sell mutual funds that day. It will take the mutual fund ticker, grab the holding and composition data from Morningstar, and then will attempt to get the information about all of the holdings and predict a percentage increase. This gives me a rough idea as to whether or not today is a good day to buy into or cash out of mutual funds. I always try to do the buying on low days and the selling on high days (who’d have guessed that, anyway?).
There are some inaccuracies in this, of course. In addition to the ones listed above, there’s also the fact that bond prices / yields aren’t always published individually, so funds have hold bonds aren’t very well predicted. Also, mutual funds only usually publish their holdings quarterly, so as the quarter goes on, the holding percentages might change, but this can only predict based on the data known from the last publishing.
Anyway, like my TSP script, I am hosting and developing it on GitHub: https://github.com/elaske/mufund. I’ve added a bunch of issues describing some of the features I wish to implement in the future, along with the goals of this initial script. Comment on GitHub or here if you have any suggestions!
![]() I’m a person that likes to keep track of their finances intently, along with someone that likes a lot of data and looking through that data. Unfortunately, these two desires start to fall apart once it gets to my retirement. As a federal employee, I have the “Thrift Savings Plan” for my funded retirement savings. The TSP is great in a lot of ways; for instance, it’s got expense ratios on it’s funds that are an order of magnitude lower than the lowest funds elsewhere (0.027%). It keeps these expense ratios low (along with the expenses to the government) by limiting a lot of things that you might find in other private retirement systems. For instance, we have only 5 funds to invest in, and another 5 “lifecycle” funds that invest in those 5 funds adjusting their allocations automatically.
I’m a person that likes to keep track of their finances intently, along with someone that likes a lot of data and looking through that data. Unfortunately, these two desires start to fall apart once it gets to my retirement. As a federal employee, I have the “Thrift Savings Plan” for my funded retirement savings. The TSP is great in a lot of ways; for instance, it’s got expense ratios on it’s funds that are an order of magnitude lower than the lowest funds elsewhere (0.027%). It keeps these expense ratios low (along with the expenses to the government) by limiting a lot of things that you might find in other private retirement systems. For instance, we have only 5 funds to invest in, and another 5 “lifecycle” funds that invest in those 5 funds adjusting their allocations automatically.
One of the main things that bugs me about it, though, is that there’s no way to see the data. You get your quarterly statements to see your performance, but that’s about it. Unlike funds that you can find data for on Google Finance, you can’t see your TSP fund’s individual or combined performances during different periods. I can’t see how my retirement funds react as a whole to world news, economic cycles, or even compare it simply to my brokerage account or IRAs. Read More
Now that we’ve got the system prepped for the installation, it’s time to start it!
First, we have to download JIRA. The only way to get the older versions is to look at Atlassian’s JIRA Downloads Archive. Remember, 5.2.11 is the latest version that is able to be installed on the Synology products with DSM 4.3 or lower. DSM is only a 32-bit operating system, so make sure to download the 32-bit version of JIRA. Also, to make everything easy, we’re going to use Atlassian’s linux installer – after all, that’s why we did all this prep! To save some time, here’s the link for the download that I used: http://www.atlassian.com/software/jira/downloads/binary/atlassian-jira-5.2.11-x32.bin